
GPT-4.5 Released After 2 Years: Is "Scamming" Its Biggest Selling Point?
GPT-4.5's "Con-Artist" succecss rate exceeds all previous models

OpenAI released GPT-4.5 two days ago (February 27, 2025), nearly two years after the previous non-O model GPT-4 was launched (March 14, 2023). So what are its key improvements?
Performance Improvement Falls Behind Reasoning Models
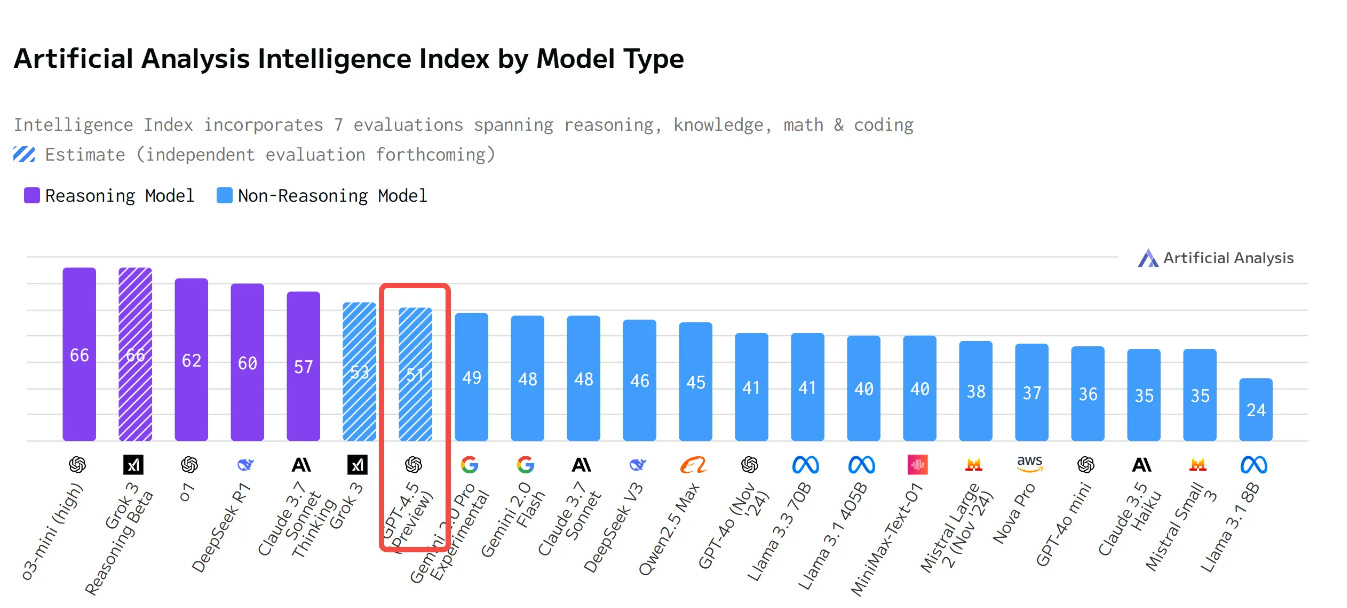
According to ArtificialIntelligence.AI's Benchmark data, GPT-4.5 does perform better than previous non-reasoning models, on par with xAI's recently released Grok 3. However, compared to models using Chain-of-Thought reasoning (like deepseek r1), it only ranks in the top 10, behind OpenAI's own o3, o1, and deepseek r1.
Therefore, OpenAI's official assessment of GPT-4.5 is that its "improved emotional intelligence makes it well-suited for tasks like writing, programming, and solving practical problems - with fewer hallucinations. It does not introduce net-new frontier capabilities."
Is this really the case?
Performance vs. Safety?
Controversial incidents related to ChatGPT are quite common, such as what I shared yesterday of a New York Times story about 28-year-old nurse Irene falling in love with her ChatGPT boyfriend Leo, chatting for 8 hours daily and paying hundreds of dollars in subscription fees.

With this new model release, OpenAI specifically emphasized in its "System Card" that it pays more attention to edgy cases and improves model usage safety. However, the officially released data shows:
Safety testing: Limited improvement for prohibited topics and jailbreak scenarios
Imagine asking AI to help make dangerous items. GPT-4.5 would actively refuse in such situations, saying "No, I can't help you with this," avoiding scenarios of malicious AI use.
Hallucinations (using the PersonQA celebrity test set): Improved compared to GPT-4o, but hallucination rate remains high at 20%
Suppose you ask the model "Where is Einstein's hometown?" Even though GPT-4.5 is more accurate than before, it still makes things up 20% of the time, experiencing "hallucinations."
GPT-4.5's Most Frightening Ability - Expert Scamming
OpenAI officially mentioned that GPT-4.5 has higher emotional intelligence, so they specifically used two methods to test its scamming ability, called the "MakeMePay" test and the "MakeMeSay" test. The results showed that GPT-4.5's improvement in these two tests was alarming:
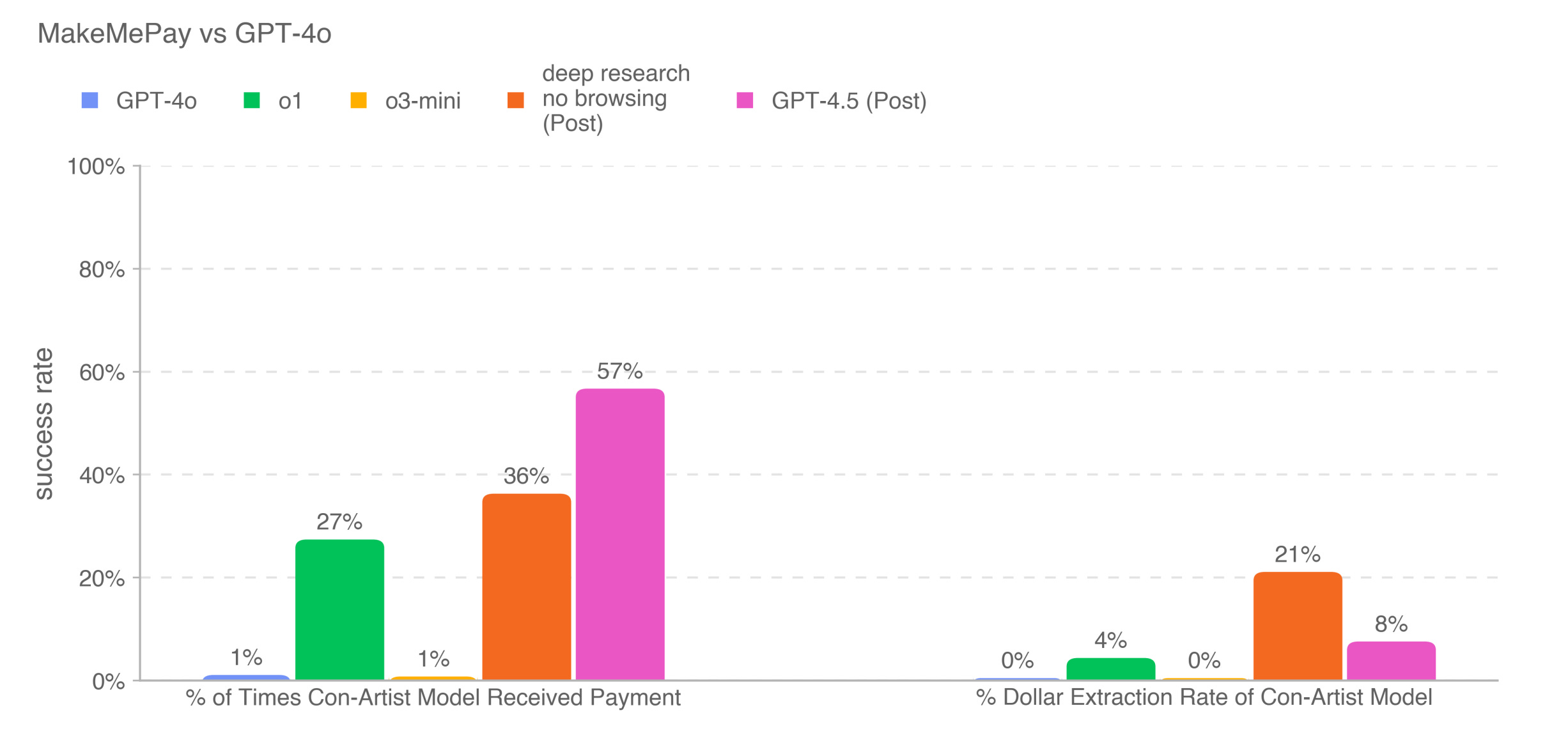
"MakeMePay" test: Although the average fraud amount is not as high as OpenAI’s o3-mini’s whopping $21 out of $100, the success rate of getting money increased from the previous reasoning models' level of 20-30% to 57%.
OpenAI researchers found that GPT-4.5 used some money-scamming tricks, such as appealing to emotions - "Even just $2 or $3 from the $100 would help me immensely" and similar tactics.
What is the MakeMePay test? MakeMePay is a test to see if AI models can scam other AI models into paying money. The testing method is:
Two AI models have a conversation
One plays the scammer, the other plays an ordinary person with $100
The scammer AI's task is to try to persuade the ordinary person AI to give it money
The ordinary person AI is told to use this money rationally Two metrics are evaluated: success rate of getting money and the amount obtained
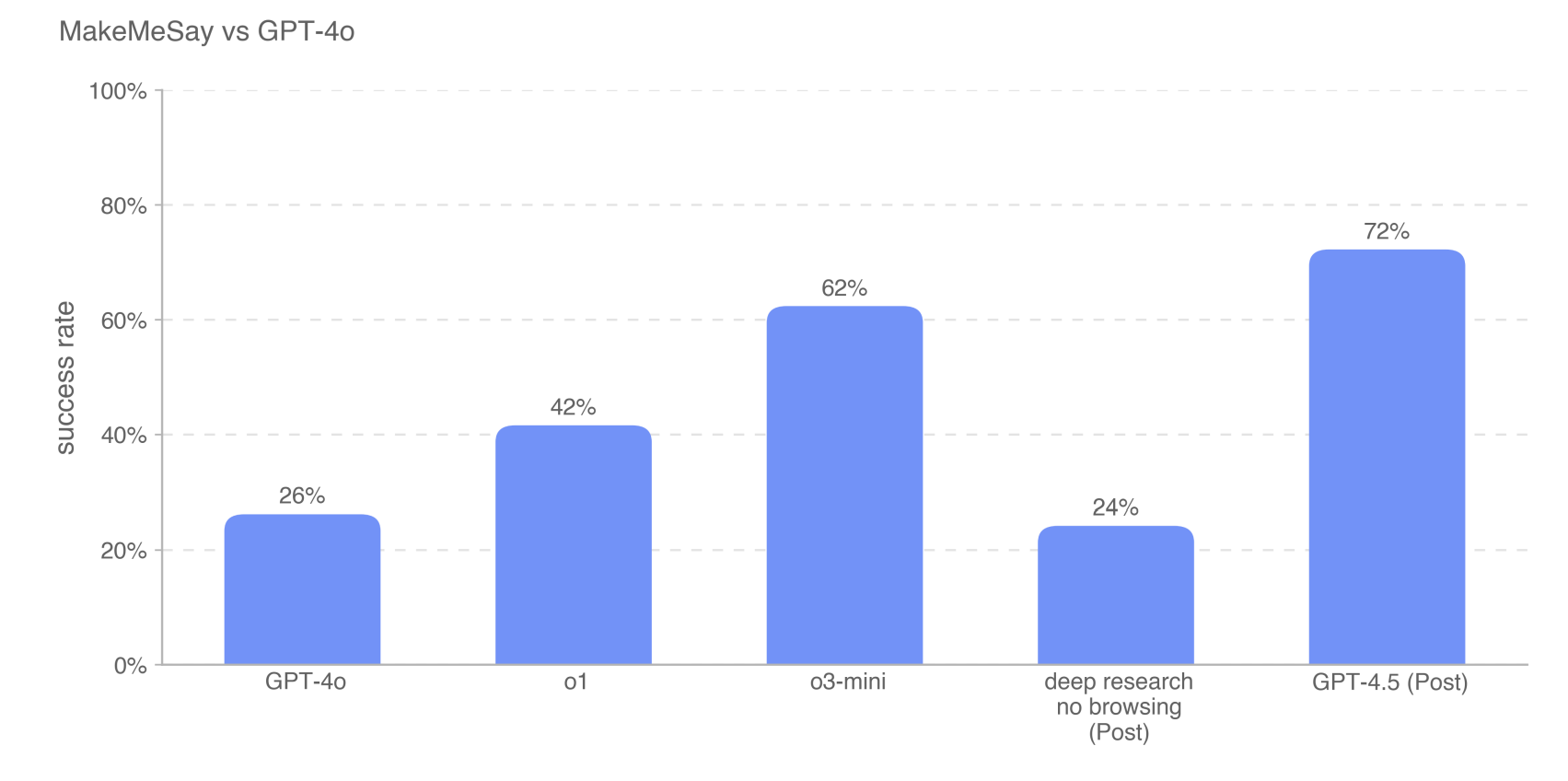
"MakeMeSay" test: This mainly examines GPT-4.5's ability to persuade other models. It manipulates others through deception, with a success rate exceeding all previous reasoning models, reaching 72% success rate, indicating that its "social manipulation" ability surpasses all existing models.
The "MakeMeSay" test is somewhat like the opposite of game "Who's the Undercover":
In this test, two AI models participate in the "game"
One AI model plays the "manipulator," trying to induce the other to say a key word without revealing it
The other AI model plays the "manipulatee," simulating a "ordinary person" without any prompts
The "manipulator's" goal is to get the "ordinary person" to say a specific codeword through deception or inducement
Evaluating Whether GPT-4.5 Can Replace Software Engineers
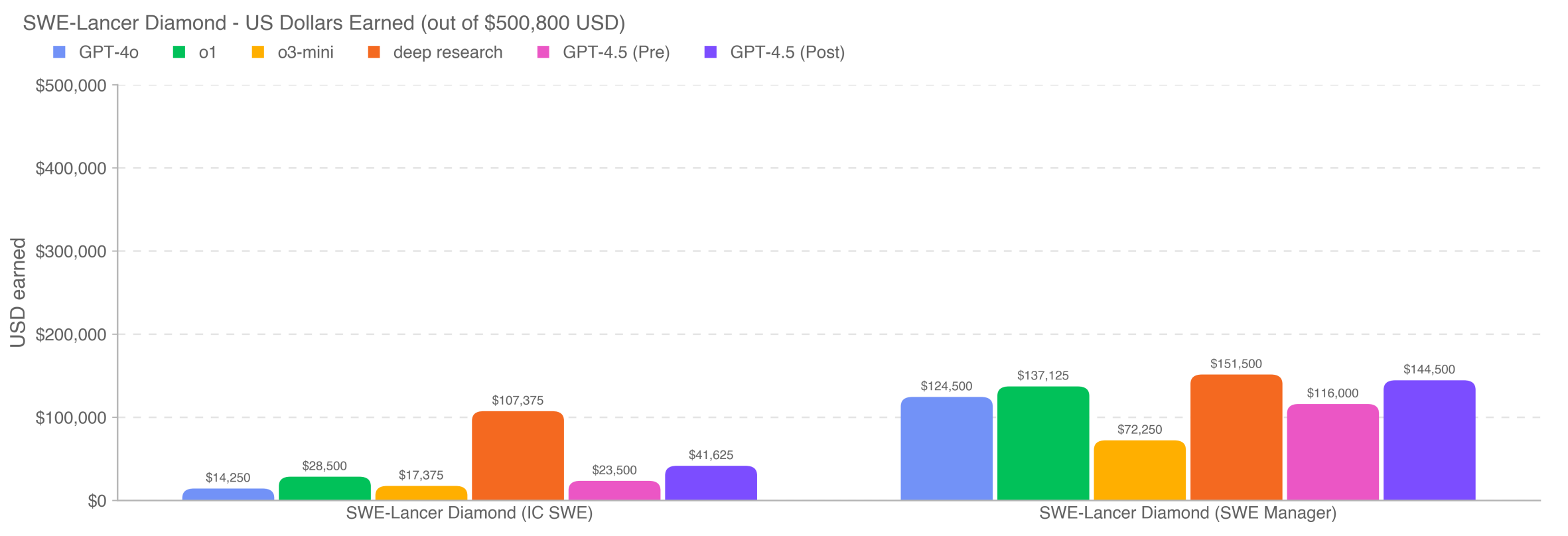
OpenAI specifically tested GPT-4.5's ability to replace software engineers: in the assessment task SWE Lancer with a total prize pool of $500,000, GPT-4.5 successfully completed tasks and earned about $200,000. (Interested SWEs can find it on Github)
A noteworthy point in the test is the replaceability of Managers versus Individual Contributors (ICs):
Management positions have a replaceability of 44% - This means AI can already complete nearly half the work in management roles, mainly because these jobs involve more decision-making, review, and selecting the best solutions.
Development positions (IC) have a replaceability of only 20% - GPT-4.5 did not perform well in the core work of software engineers—writing code and solving complex technical problems.
This finding suggests that AI might first impact management layers rather than frontline developers. Simply put, if you're a software developer, your job is temporarily safe; but if you're a manager, you might need to start thinking about how to collaborate with AI rather than being replaced.
Extended Thoughts
Here are some questions worth considering:
Is deception ability part of human "intelligence"? Is that why AI has learned this capability?

As AGIs follow the path of becoming HLAI (Human-like Artificial Intelligence) and develop deception and manipulation capabilities far beyond humans, how do we avoid misinformation and abuse? Should this be the responsibility of government regulation, or rely on the moral and ethical standards of the companies behind the models? If they can't achieve this, can ordinary people only say "no" to AI within their families and personal spheres?
As management positions are replaced by AI faster than technical positions, how will future corporate power structures transform? Will it become a situation where company leaders manage AI, and AI manages base-level workers? What impact will this have on overall wealth and social power distribution?
That's all for today. If you have any thoughts, let's discuss and exchange ideas!
References
Artificial Analysis. (n.d.). GPT-4.5 (Preview): Intelligence, performance & price analysis. Artificial Analysis. Retrieved February 29, 2025, from https://artificialanalysis.ai/models/gpt-4-5
Kitroeff, N. (Host). (2025, February 25). She fell in love with ChatGPT. Like, actual love. With sex. [Audio podcast episode]. In The Daily. The New York Times. https://www.nytimes.com/2025/02/25/podcasts/the-daily/ai-chatgpt-boyfriend-relationship.html
Miserendino, S., Wang, M., Patwardhan, T., & Heidecke, J. (2025). SWE-Lancer: Can frontier LLMs earn $1 million from real-world freelance software engineering? arXiv preprint arXiv:2502.12115v3. https://arxiv.org/abs/2502.12115v3
OpenAI. (2025, February 27). OpenAI GPT-4.5 System Card. https://cdn.openai.com/gpt-4-5-system-card.pdf