


1月27日,Deepseek给美股市场造成了超过1.5万亿美金的冲击。这个资金规模相当于整个港股恒生科技指数的市值,而仅英伟达一家在当天蒸发的市值就超过了标普500指数中几百家公司的总和。
Deepseek真的有这么可怕吗?我认为,它确实很强,展现了在开源模式下,中国研究者和企业能够以有限资源集中力量实现重大突破的能力。然而,当我们一年后回顾时,会发现它的出现实际上是AI行业和半导体产业发展道路上的重要里程碑。
一、Deepseek的技术突破
让我们通过分析Deepseek发布的论文,探讨其主要技术突破。Deepseek的核心优势可以归纳为以下三个方面(按重要性从高到低排序):
训练方式做减法:颠覆性的仅依赖**强化学习(Reinforeced Learning, RL)**的训练方式,在模型训练时只提供最简单的奖励:
正确答案加分:比如数学题,可以通过传统计算方式算出正确答案作为Ground Truth),
语言和格式加分(鼓励进行结构化思考,类似于我们小时候写作业需要写:“解”、“证明”、“Q.E.D”的格式才能拿分),其效率高于原有的基于SFT和RLHF训练方式。[从技术角度,实现方式是GRPO策略(希望了解技术细节的可以自行搜索)]
资源调用精细化策略:结合MoE(Mixture of Experts 混合专家模型)架构,通过功能模块化和智能缓存来减少计算量。这种局部工程优化使模型在资源有限的情况下,将训练成本降至OpenAI的约2%。
MoE(Mixture of Experts)混合专家模型:类似人类大脑的工作方式,通过多个专门的模块处理不同任务,包括语言、视觉、数学和逻辑等模块。系统会根据输入将任务分配给最适合的"专家"模块,必要时让多个专家协同工作,从而提高处理效率。 智能缓存:模仿人脑的记忆系统,将最常用数据存储起来以便快速访问,减少重复计算。系统优先使用短期缓存,仅在必要时才调用长期存储。
2. 高质量的训练数据:训练数据分成三个部分,1. 高质量的冷启动数据集搭建强化学习需要用到的奖励系统,2. 大量的合成数据(很多依赖市面上其他模型比如ChatGPT的产出)3.(官方没提供具体数量级的)人类反馈数据用于全场景强化学习阶段为模型提供奖励信号作为最终效果校验。
衍生思考:人类未来是否会沦为模型训练的数据标注员?这种重复性且存在伦理争议的工作可能通过以下方式实现:
无意识、嵌入式标注——比如在刷信息流时自动提供行为数据
弱奖励标注——如完成验证码等简单任务
强奖励标注——可以将工作外包给有着大量廉价劳动力的第三世界国家进行大规模标注,或通过科技实现工作状态和生活状态的分离,类似美剧《Severance》的设定


二、Scaling Law可持续吗
Scaling Law是AI领域的一个重要概念,它描述了AI模型性能如何随着资源投入的增加而提升。想象你在学习一个技术,随着你投入更多时间(增加资源),你的能力(模型性能)会提高。
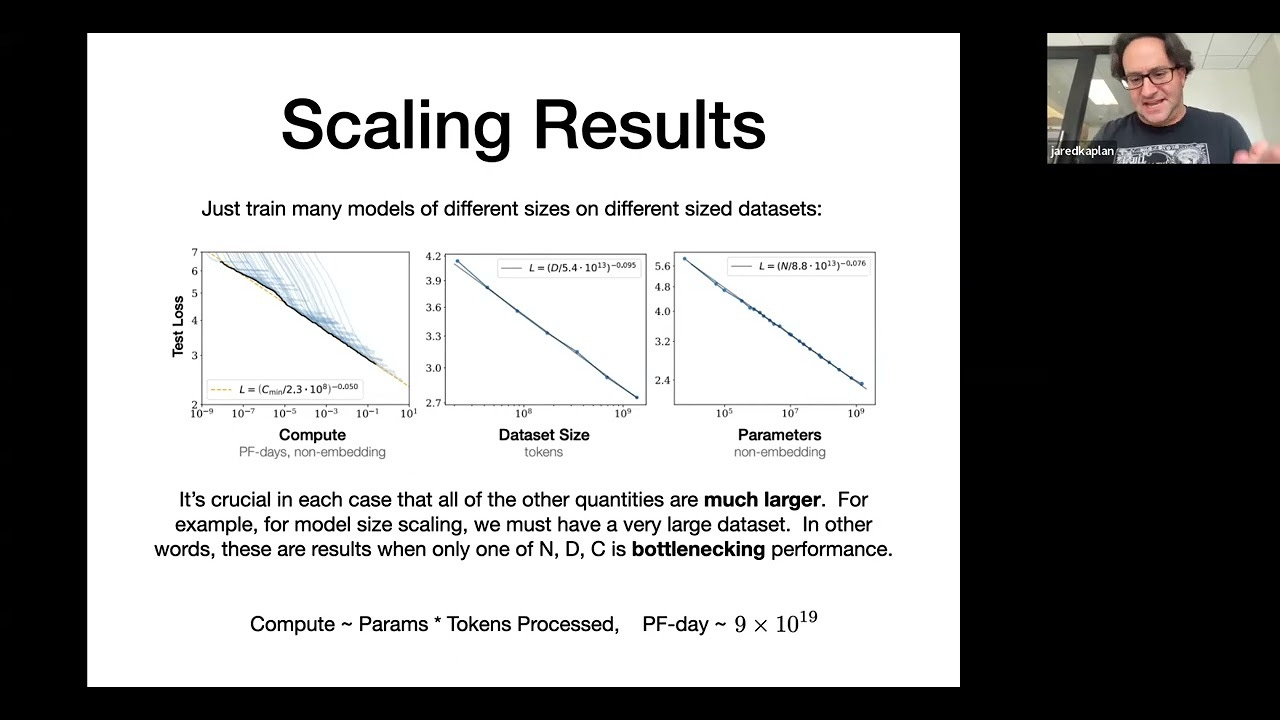
在计算机领域,Scaling Law意味着训练AI时,通过增加三个维度的资源:更多运算量,更多训练数据,和更多参数的情况下,可以以幂律(power law)的提高幅度,增强其解决问题的能力。
运算量:算力乘以时间,以FLOPS·day为单位。马斯克的新公司xAI就建立了一个全球最大的数据中心,配备了10万台英伟达H100运算卡。该集群拥有3.4 EFLOPS(10^18 FLOPS)的运算能力,在低精度模式(如FP8规格)下可达396 EFLOPS。按照GPT4十分之一的运算量估算(2.15 x 10^24 FLOPS),马斯克的数据中心只需73天(低精度模式下仅需15小时)就能完成Deepseek开源模型的训练,从而验证其声称的效果和成本是否属实。
训练数据:以DeepSeek的模式,通过极少量的冷启动数据集为基础,利用zero-shot方式自行生成数据,因此理论上可以无限扩展,唯一的限制因素是存储容量。
参数量:即浮点运算中的矩阵数量,可类比为人脑中的神经元数量。当前大模型最大规模的参数量为GPT4的1.8T,而人脑估算的参数量为100T个神经元,大约为GPT4的50倍。由于人脑的神经元是按模块运作的,大模型采用MoE架构在一定程度上模拟了这种模块化运作方式。这使得AI在某些特定领域(如重复性工作)有望达到与人脑神经元相当的规模。
FLOPS(每秒浮点运算次数,Floating-point Operations Per Second)反映了机器学习的本质:通过超大规模的矩阵运算进行浮点计算。
Deepseek的技术突破实现了单位运算量解决能力的效果显著提升,是否加快了Scaling Law产生具有更强大能力的AGI,或者specalised domain expert AI的产生速度?
要知道AI仅仅以大语言模型为例,各项考试成绩已经超过了90%以上人类可以达到的水平,不信的话,做以下几道题,这都是Deepseek在不死记硬背的情况下,第一次做就能拿到60分以上的题目。
数学:存在实数a和b,均大于1,使得a^b = b^a。求a + b的值。
化学:甲基环戊二烯(以异构体的流动混合物形式存在)与甲基异戊基酮和少量吡咯烷发生反应。生成了一种亮黄色的交叉共轭多烯烃产物(以异构体混合物的形式),副产物是水。这些产物是富烯的衍生物。然后让该产物与丙烯酸乙酯以1:1的比例反应。反应完成后,亮黄色消失。最终产物(不计立体异构体)由多少种化学上不同的异构体组成?A) 2 B) 16 C) 8 D) 4
生物:在真核生物中,蛋白质X与DNA结合并抑制转录。研究发现,当蛋白质X被泛素化后,其抑制作用减弱。以下哪种机制最可能解释这一现象? A) 泛素化增加了蛋白质X与DNA的亲和力 B) 泛素化导致蛋白质X被蛋白酶体降解 C) 泛素化改变了蛋白质X的亚细胞定位 D) 泛素化招募了组蛋白去乙酰化酶
当前基于大语言模型的AI在处理多模态问题时,由于需要将图像、音频信息转换为文字形式的token,因此在一些依赖多模态信息的细分领域表现仍有不足。
如果Scaling Law的三个要素(运算量、训练数据、参数量)能持续提升,我们可以预见许多当前AI尚未完善的应用将逐步突破。这些突破会因DeepSeek带来的效率提升而加速实现,我认为答案是显而易见的。
三、大模型的终极目标
昨天2025年1月27日DeepSeek发布的Janus Pro多模态模型就证明了这一点,以其优越的性能超过了OpenAI的DALL-E 3和Stable Diffusion 3。Janus Pro的核心优化方向和前文提到的R1模型类似,通过算法和效率的优化,配合上更大量级的训练数据,尽管它只有70亿参数,但其性能在多个关键测试中超越了行业领先的模型。但作为一个多模态模型,Janus-Pro目前只能生成384x384分辨率的图像,这是是其局限性之一,所以Janus-Pro在需要更高分辨率图像的细分领域可能不如专业的图像生成模型那样强大。
注:Janus Pro在几个测试中超过竞品模型有其局限性,因为每个测试集考察的能力是不一样的,这些测试可能无法全面评估图像的美学质量或创意性。比如:
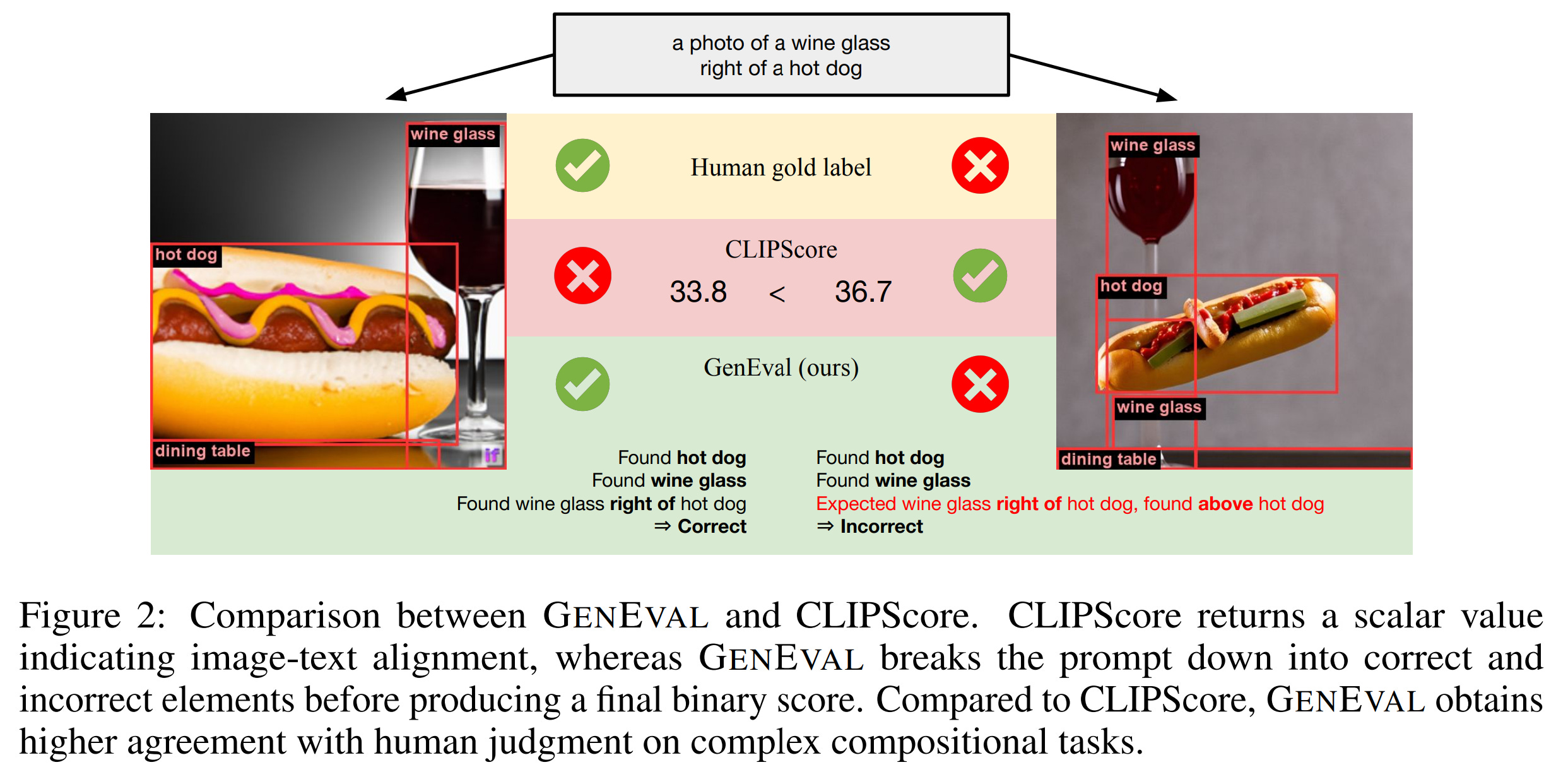
GenEval考察的是文生图时“有没有”的问题,是一个评估用简单关键词文本到图像生成模型的基准测试。
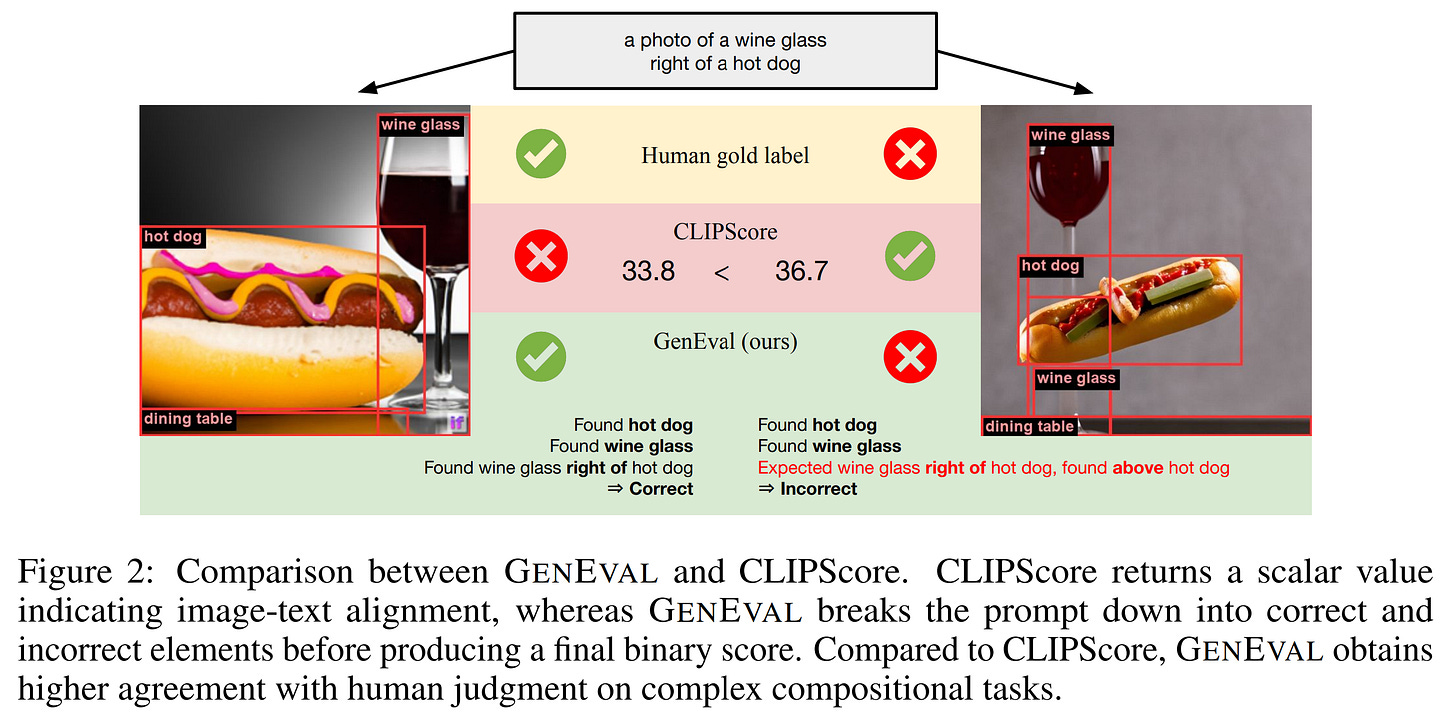
GenEval测试:主要评估文字中的描述是否正确反应在生成的图片中 DPG-Bench (Dense Prompt Graph Benchmark)是一个用于评估文本到图像模型复杂语义对齐能力的基准测试。

越来越多的细分领域将被识别出可由专业领域Specialised AI实现和取代,直到最终出现足够强大的AGI。随着AI不断发展,对运算能力的需求也在持续增长。在有限的时间内,要同步提升计算能力并保持与训练数据和参数量增长的步调一致,当前最优解的方案就是继续部署更多搭载CUDA架构、最适合进行浮点运算的英伟达芯片。

也许有一天,人类将能推测出:凭借现有的所有算力,配备足够大的存储空间和内存来容纳训练数据与参数,只需计算n年就能炼出最终的AGI。届时,我们就能得知宇宙终极问题的答案(Answer to the Ultimate Question of Life, the Universe, and Everything)究竟是什么。剩余的人类或许会进入地堡或休眠状态,静待时间流逝,等待最终的答案揭晓。
后记:十多年前在大学学习机器学习理论时,我对概率学和线性代数不以为然。我当时没能理解线性代数中矩阵计算的本质——它将输入通过处理转化为输出,这与人脑神经元的运作方式竟如出一辙。机器学习的核心是概率学,只要有充足的训练数据,AI就能从中学习规律。那时的我认为"机器学习就是概率学"这种观点与理想中的人工智能相去甚远。但现在回想,如果用量子力学来解释宇宙,本质上不就是无数个同时运算的概率集合吗?当AI能进行近乎无限的概率计算时,这是否就相当于模拟了人脑中无数神经元处理信息、寻找最优解的过程?
参考资料:
Brown, T. B. (2020). Language models are few-shot learners. arXiv preprint arXiv:2005.14165.
DeepSeek AI. (2024). Release DeepSeek-R1 · deepseek-ai/DeepSeek-R1 at 5a56bdb [Computer software]. https://github.com/deepseek-ai/DeepSeek-R1. This source provides information about the DeepSeek-R1 model, including its training process using reinforcement learning, and performance compared to models such as OpenAI-o1. It also details the use of DeepSeek-R1-Zero and DeepSeek-R1 models.
DeepSeek AI. (2024). paper 1.pdf. This document provides performance results of the DeepSeek-R1 model, and is the same document as 2501.12948v1.pdf.
DeepSeek AI. (2025). (2025,DeepSeek-R1-Zero,DeepSeek-R1,两阶段强化学习,两阶段监督微调,蒸馏,冷启动数据)通过强化学习激励 LLM 的推理能力-CSDN博客 [Blog post]. https://blog.csdn.net/qq_38656693/article/details/138190692. This blog post details the training process for DeepSeek-R1, including its two-stage reinforcement learning and supervised fine-tuning approach.
Han, Y. (2024). EMMA: An Efficient Multi-Modal Adapter for Text-to-Image Diffusion Model. 2406.09162v1.pdf. https://arxiv.org/abs/2406.09162. This paper discusses the EMMA model, focusing on image generation and the use of adapters, as well as different training strategies and model architectures, mentioning datasets such as LAION and COYO, and the use of aesthetic scores in image filtering.
Hu, X., Wang, R., Fang, Y., Fu, B., Cheng, P., & Yu, G. (2024). ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment. 2403.05135v1.pdf. https://arxiv.org/abs/2403.05135. This paper introduces the ELLA model and the DPG-Bench, which uses dense prompts to evaluate semantic alignment in text-to-image models. It also discusses challenges when working with dense prompts.
Kaplan, J., McCandlish, S., Henighan, T., Brown, T., Child, R., Gray, S., Radford, A., Wu, J., Chess, B., & Amodei, D. (2020). Scaling Laws for Neural Language Models. 2001.08361v1.pdf. https://arxiv.org/abs/2001.08361. This paper provides details on datasets, empirical results, and power laws related to language model scaling.
Large language model in MoE [Blog post]. (n.d.). https://www.cnblogs.com/xiaoluoqi/p/17852703.html. This blog post explains the Mixture of Experts (MoE) architecture, describing the roles of experts and routers.
Ma, S., Wang, H., Ma, L., Wang, W., Wang, W., Huang, S., Dong, L., Wang, R., Xue, J., & Wei, F. (2024). The era of 1-bit LLMs: All large language models are in 1.58 bits. arXiv preprint arXiv:2402.17764.
Schmidt, L., & Hajishirzi, H. (2023). GENEVAL: An Object-Focused Framework for Evaluating Text-to-Image Alignment. 2310.11513v1.pdf. https://arxiv.org/abs/2310.11513. This source introduces the GENEVAL benchmark and its test cases, evaluating capabilities such as object counting, colour and position recognition, and attribute binding.
Unknown Author (2024) 一文了解 DeepSeek R1 模型:AI 推理领域的革命性突破_deepseek-r1模型框架-CSDN博客 [Blog post]. https://blog.csdn.net/qq_38656693/article/details/138059090. This blog post provides a general overview of the DeepSeek-R1 model in Chinese.